
The Memory Layer: How Vector Databases Transform AI’s Ability to Reason
Why organizations need structured memory systems to unlock accuracy, safety, and sector-specific intelligence.
Executives are discovering a hard truth about generative AI: the model is confident long before it is correct. I’ve seen it in the work that we’ve been doing when creating generative AI (GenAI) implementations for clients. They make mistakes. Very convincing mistakes.
Left on its own, a large language model will answer almost any question you ask, even when it has no solid basis for doing so. For experimentation, that is tolerable. For strategic decisions, regulated environments, or client-facing interactions, it is a problem. That problem, as you’ve undoubtedly heard it called, is hallucination. I don’t like the term itself, but it’s what seems to have stuck.
Vector databases have emerged as one of the most important tools for turning GenAI from an impressive demo into a dependable system. They do not eliminate hallucinations, but they significantly reduce them and, more importantly, make AI behaviour much more controllable.
I was discussing this with a client recently and realized that perhaps this was a topic worth unpacking, not only for them, but for all my readers. What I’m hoping to do in this article is explain the core problem, how vector databases work, how they help, and then show what this looks like in concept for three sectors: education, healthcare, and insurance.
The Problem: Why Large Language Models Hallucinate
Large language models are, at their core, probability machines. They learn patterns from vast amounts of text and then generate the next word that is statistically most likely, one token at a time. I’ve told audiences many times, there is no actual intelligence in today’s AI. Just patterns.
Several consequences follow when you have this inside your organization:
They do not know what your organization knows.
They are trained on the general world, not your specific curriculum, clinical guidelines, or policy documents.They are not designed to say “I do not know.”
The safest answer from a probabilistic model is often a fluent guess rather than silence.They blur the line between “typical” and “true.”
If a statement looks linguistically plausible, the model will often produce it, even if it is factually wrong, outdated, or incompatible with your internal rules.
This leads to hallucinations, especially when:
The question is niche or domain-specific.
The answer depends on local policies, contracts, or procedures.
The user assumes the system has access to private or proprietary information when it does not.
For leaders, the issue is not only accuracy. It is trust, accountability, and the ability to explain where an answer came from. That is where vector databases change the structure of the problem.
What A Vector Database Is, In Plain Language
Traditional databases work with structured fields: rows, columns, and exact matches. Traditional search engines work mostly with keywords. Both operate on surface forms of text.
Vector databases work on meaning.
The key building block is an embedding. An embedding model converts text into a long list of numbers, often hundreds or thousands of dimensions. You can think of those numbers as coordinates that place the text in a semantic space where:
Sentences with similar meaning end up near each other.
Sentences about very different topics are far apart.
For example, the sentences:
“Grade 7 inquiry-based learning rubric”
“Assessment criteria for middle school inquiry projects”
look different as strings of characters, but as vectors, they might be very close together.
When you take documents from your organization and ingest them into an AI solution, it creates these vectors and those vectors in turn need to be stored in, you guessed it, a vector database. At its core a vector database:
Stores many such embeddings for your documents, along with references back to the original text.
Builds an index that supports very fast similarity search, which answers questions like “what are the top N stored vectors closest to this new one?”
In other words, it allows you to ask: “Given this new question, which pieces of my content are most semantically similar?”
This is fundamentally different from keyword search:
Keyword search: “Find documents where ‘Grade 7’ and ‘inquiry’ both appear.”
Vector search: “Find documents whose meaning is closest to ‘What do we expect students to demonstrate in Grade 7 inquiry work?’ even if those exact words never appear.”
With this building block, you can change how your AI systems use knowledge.
How Vector Databases Reduce Hallucination
Vector databases by themselves do not generate text. They support a pattern known as retrieval augmented generation(RAG).
When a user asks a question, the system does not simply hand it to the model and hope for the best. Instead, it follows a disciplined process:
Turn the question into a vector.
The question is embedded into the same semantic space used for your documents.Retrieve relevant content.
The vector database finds the most similar embeddings and returns the associated passages from your internal knowledge: policies, guidelines, curricula, contracts, historical decisions.Construct a context.
The system builds a prompt that includes both:the user’s question, and
a curated set of relevant excerpts from your documents.
Constrain the model.
The model is explicitly instructed to answer based only on the provided context and to say it cannot answer if the context is insufficient.
Because the model is now “reading” the correct internal content at the moment of answering, several good things happen:
It is much more likely to quote or summarize actual organizational knowledge instead of improvising.
You can trace an answer back to its sources.
You can build guardrails. For example: “If no relevant passages are found, ask a clarifying question instead of answering.”
Hallucination does not disappear entirely, but it changes character. It becomes a design and governance issue: Are you indexing the right data, chunked appropriately, with sensible relevance thresholds and prompts?
Now the problem is tunable rather than mysterious. That’s why you will hear data scientists and AI engineers using the phrase “tuning the model”, the settings above are literally and iteratively tuned to get to a result that best fits your orgnization and your users.
With the mechanics in place, the concept becomes easier to understand in concrete settings.
Education: Turning Institutional Memory Into A Reliable Guide
Education is awash in documents that carry institutional intent. Curriculum maps, course outlines, assessment frameworks, rubrics, policies on student life and academic integrity, wellness protocols, meeting notes, strategic plans, accreditation reports, LMS content, handouts, archived communications, admissions interview notes. Leaders will tell you that “it is all in there somewhere,” often underestimating the friction involved in actually finding a clear, up-to-date answer.
For a busy educator or administrator, the practical reality is that a specific question often leads to rummaging through shared drives, guessing at filenames, and reusing whatever version of a document appears first. Informal interpretations fill the gaps. Over time, this erodes consistency and creates quiet misalignment between the official stance and day-to-day practice.
A vector database shifts this dynamic. When every policy, program document, and rubric is embedded and indexed for meaning, educators can interact with the institution’s knowledge in a completely different way.
A teacher can ask, in natural language, what evidence is expected for Grade 7 inquiry in science, or how interdisciplinary learning is being defined in the middle school, or what the current policy is on extended time for assessments. Instead of scanning through multiple PDFs, the system retrieves the passages that most closely match the intent of the question and presents them in a form that the model can quote, summarize, or clarify.
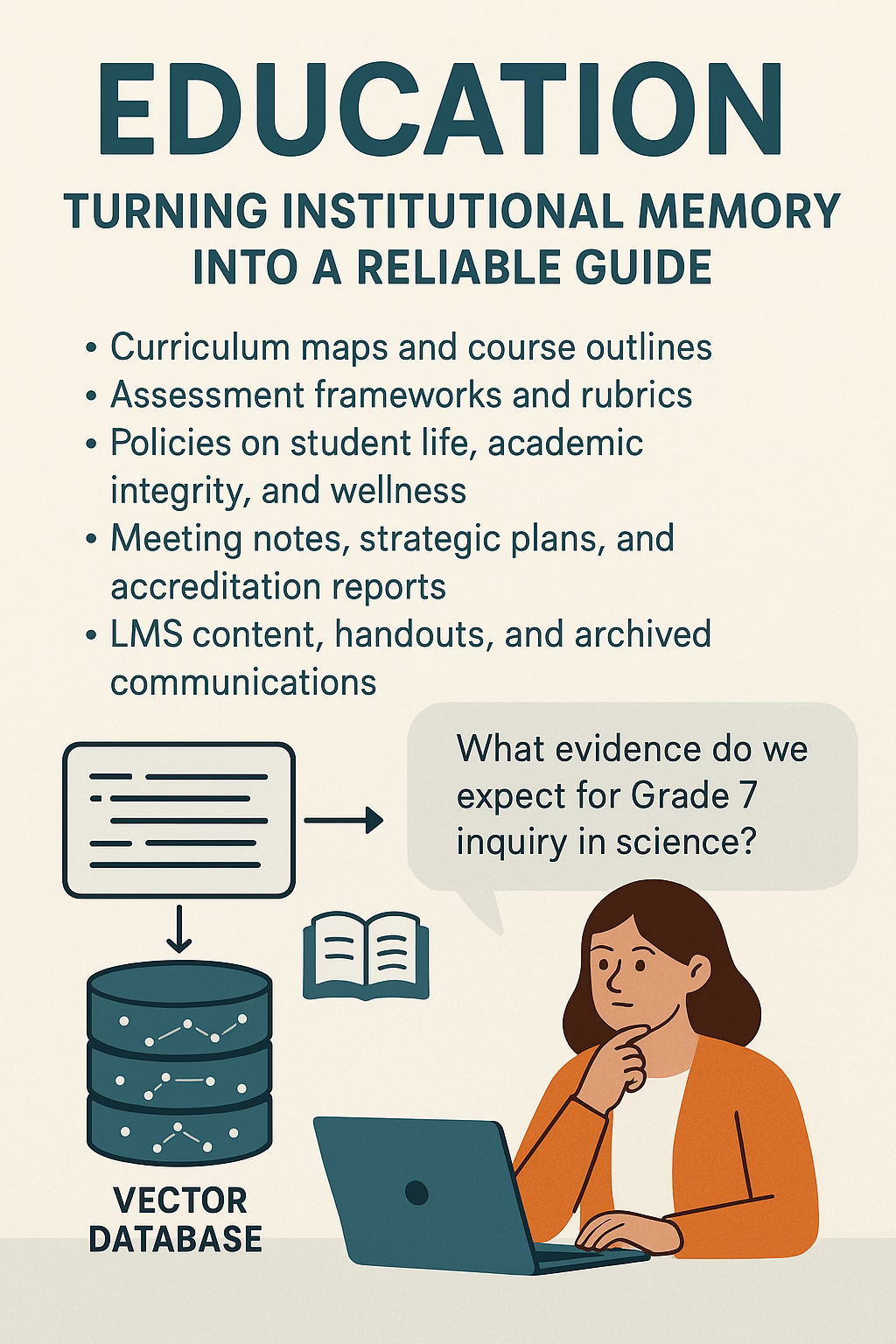
The result is not just convenience. It is a quiet form of governance. Different staff members are now drawing on the same textual source rather than circulating folk wisdom. Leadership can see which documents are most frequently referenced, which questions keep recurring, and which policies appear to invite confusion. The retrieval patterns themselves become a diagnostic signal for strategic improvement.
In a sector where trust with families, coherence across grades, and alignment with stated values all matter deeply, a vector-backed knowledge layer functions as a kind of institutional compass. It does not replace professional judgment. It simply makes the official record easier to access, easier to apply, and easier to refine.
Healthcare: Grounding AI In Protocol, Not Guesswork
Healthcare combines massive information complexity with very low tolerance for error. The potential upside of generative AI is significant: help with documentation, faster access to guidelines, better summarization of patient histories, and more responsive support for clinicians. The downside of a confident hallucination, however, is not theoretical. It has clinical, legal, and ethical weight.
Clinicians and administrators operate within a dense web of clinical pathways, best practice guidelines, local hospital policies, order sets, formularies, drug interaction references, consent procedures, regulatory requirements, and accreditation standards. Even within a single institution, the difference between “what we could do” and “what we have agreed to do here” is important.
An off-the-shelf language model does not know those local decisions. It does not know which guidelines leadership has endorsed, which protocols have been superseded, or which risk positions the institution has taken. Using such a model directly for anything beyond drafting is, at best, an informal experiment.
A vector database allows a deliberate alternative. The hospital’s validated documents can be embedded and indexed. When a resident asks about a recommended discharge planning pathway for an elderly patient with a specific pattern of comorbidities, the system can retrieve relevant sections of the discharge planning guidelines and local policies. When a nurse asks about the documentation required for consent in a particular procedure, the system consults the institution’s own procedural and consent policies. When an administrator asks about current guidelines for virtual visits in a department, the system surfaces the most recent approved protocols.
The language model still plays a role, but its job is to articulate. It is summarizing, clarifying, and explaining what the institution has already committed to in writing. The answer can be framed explicitly in terms of “according to our hospital’s protocols and these guidelines” rather than a generic “the model says.”
This approach produces a different risk profile. Clinical risk is reduced because answers align with local policy rather than generic internet text. Auditability improves because it is possible to see which guideline supported a given recommendation. Change management becomes more manageable because updating a guideline in the knowledge base directly influences what the system retrieves and, therefore, what it says.
The system still demands human judgment and strong governance. It does not replace clinical expertise. It does, however, provide a disciplined companion, rather than an improvising assistant, for those who work inside complex care environments.
Insurance: Consistency In A World Built From Language
Insurance is an industry that is also defined by text. You might think it’s numbers, but it’s just as much text. Policy wording, endorsements, exclusions, claims manuals, underwriting guidelines, and historical cases collectively describe what is covered, under which conditions, and how claims will be treated. Small differences in phrasing can carry large financial implications.
The challenge is not only complexity. It is variability in interpretation. Adjusters can read the same clause differently, underwriters can apply guidelines unevenly across regions, and brokers can explain coverage to clients in ways that are partially correct or no longer current.
Naively applied generative AI risks amplifying this variability. A model that produces smooth, confident paragraphs might misquote a clause, omit a critical condition, or gloss over a key definition. It might also synthesize wording that never appears in any official document. The result sounds professional while quietly drifting away from the binding text.
Vector databases provide a way to keep AI responses tethered to the language that actually governs decisions. When policy wordings, endorsements, guidelines, and key historical decisions are embedded and stored, questions from adjusters, underwriters, or brokers can be answered by first retrieving the precise sections that apply.
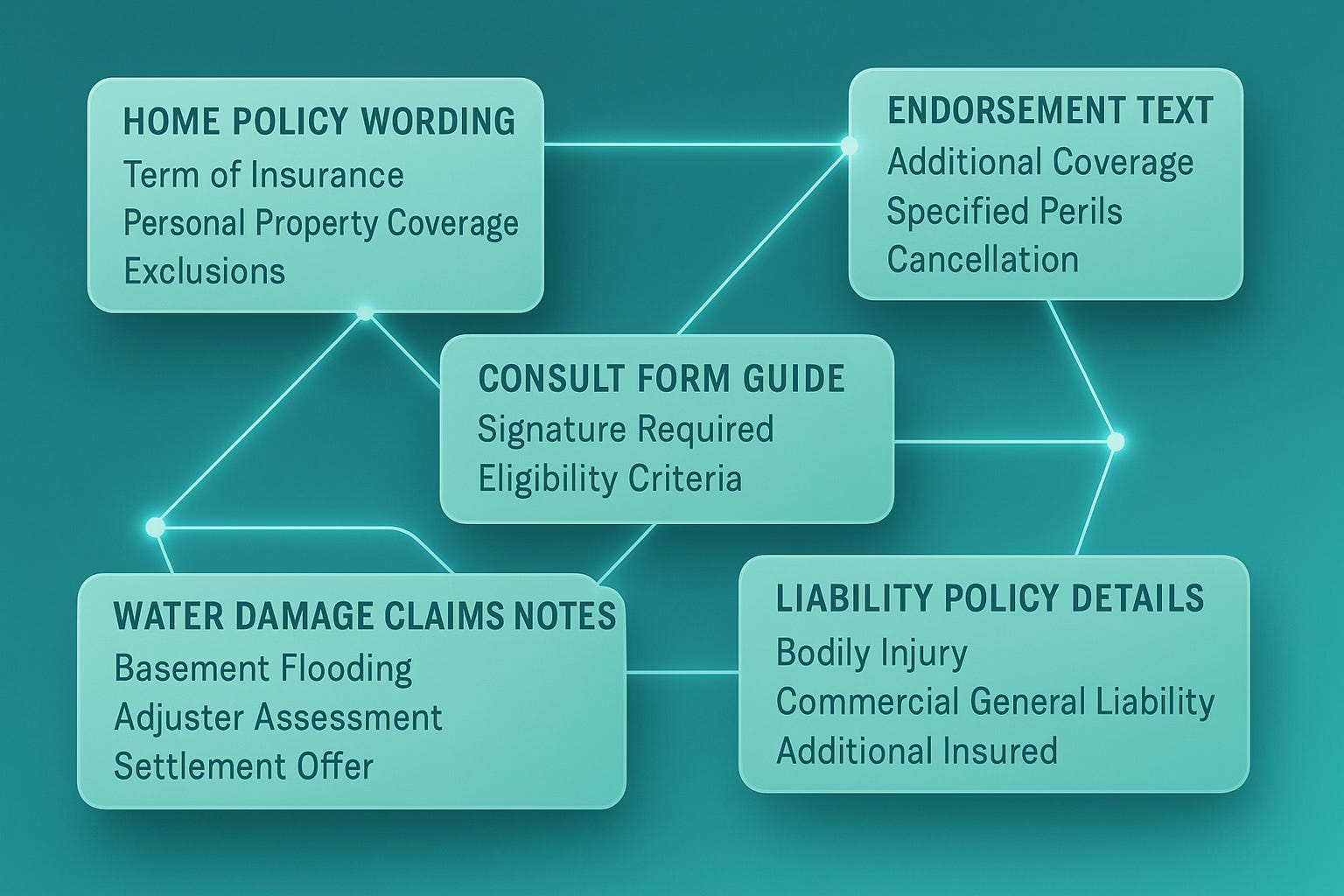
An adjuster querying whether a specific claim meets criteria for a water damage exception for homeowners in a given region can be presented with the exact clauses that define that exception. An underwriter asking about current guidelines for cyber coverage limits for a particular segment can be pointed to the relevant underwriting guide sections. A broker preparing to explain how a certain kind of business interruption scenario has historically been treated can see the most relevant precedents and policy language side by side.
The language model then serves as interpreter. It turns dense, legalistic text into explanations that a human can understand, while keeping the original wording visible and traceable. Supervisors and regulators can follow the chain from decision back to text. Client-facing staff can articulate coverage more clearly without drifting away from what the contracts actually say.
For an industry where ambiguity in wording is expensive, vector-backed retrieval does not just add convenience. It introduces a new level of consistency and explainability into day-to-day decision-making.
What Strategists Should Internalize
The underlying insight is straightforward but easy to overlook. Vector databases allow you to turn the unstructured, scattered knowledge of your organization into a semantic fabric that your AI systems can navigate in real time. They give structure to institutional memory without forcing you to predefine every field and relationship in advance.
For leadership, this suggests several priorities.
First, it puts new weight on the quality of internal knowledge assets. Policies, guidelines, procedures, reference manuals, and program documents that once lived quietly on shared drives are now potential input to automated reasoning. Their clarity, coherence, and authority matter more once they become sources for machine-mediated answers.
Second, it encourages a sharper focus on specific workflows. The highest returns will come from places where staff already spend time looking things up, where answers must be consistent, and where mistakes have material consequences. Those are the environments where anchoring AI in your own truth has the greatest impact.
Third, it shifts the mental model for AI initiatives. A serious initiative is no longer “we will put a chatbot in front of our staff.” It is “we will design a retrieval augmented system that includes a vectorized knowledge layer, carefully crafted prompts that constrain the model, and explicit behaviours for what happens when the system does not know.”
Finally, it reframes hallucination as a system design and governance question instead of a character flaw in the model. You can measure how often answers can be traced back to authoritative sources, how often uncertainty is acknowledged, and where fabrication still creeps in. Those metrics become levers you can pull by adjusting data, indexing strategies, and control logic.
Education, healthcare, and insurance all operate in worlds where trust and compliance are not optional. In each, a vector-backed approach can move AI from novelty to infrastructure, from a collection of clever demos to a dependable extension of institutional knowledge.
The organizations that will extract real value from GenAI are not simply the ones with access to the largest models. They will be the ones who build the clearest bridge between what they already know and what the machine can do. Vector databases, quietly and without much fanfare, have become one of the most important structural elements of that bridge.